|
6 d* z! q, e3 D: h6 L
原标题:同程旅行吴祥平:同程湖仓一体应用与实践本文根据吴祥平老师在【第十五届中国系统架构师大会(SACC2022)】线上演讲内容整理而成本文摘要:为了解决数仓存在的一些问题比如:数仓的实时性,资源消耗,更新需求日益变多,我们跟进业界步伐实践了从数仓到湖仓的转变。
1 V8 u3 i( h2 I, p3 S$ s1 X6 Z 目前我们将大多数hive表改造湖仓表,替换内部数仓base层hive表为hudi表,时效性由T+1降低为分钟级延迟,同时基于hudi实现了流式宽表,实时join等场景的落地,为业务降低了大量计算资源的使用。
0 p1 w4 Q+ ?5 C" ?: y. Z, L 本次分享,湖仓架构的演进实践分享内容包括:数仓架构和规模,碰到过什么问题、数据湖与数仓的区别,为什么选择hudi、湖仓架构在同程旅行的实践过程,架构演进思路是什么、湖仓实践过程中的问题等同时,对湖仓技术方案未来发展、实践经验与思考等内容。
: y' V4 z. B1 W! b. M1 l 同程旅行数仓现状在引入湖仓之前,我们采用Lambda架构数仓,一条实时链路和一条离线链路,实时链路基于Kafka和Kudu实现,离线链路基于Hive和olap引擎如GP/CK/StarRocks等加速数据应用。 6 p8 t1 r) D& T1 C9 C9 S' L
我们目前有80%的离线场景,每天8万+离线任务,40万+hive表;20%实时场景,4000+实时任务要知道Lambda架构在大数据时代主导了很长时间,但随着数据应用场景的不断丰富,实时性需求越来越多,Lambda架构的缺点就被逐渐放大。 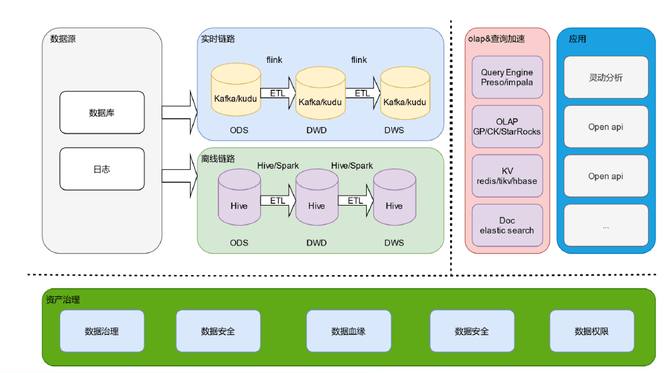 % i# a* r ~1 h8 j8 B
% i# a* r ~1 h8 j8 B 基于Lambda架构数仓痛点主要体现在四个方面:1,数据计算冗余:Binglog实时入仓,离线任务每天定时合并,且业务计算需要等待2,开发和维护困难:两条链路,逻辑一致性保障,技术要求不一样,结果往往不一样。
7 C* d3 V4 [% m8 F, s, ` 3,数据存储冗余:合并产生大量临时表,中间结果表等数据急速膨胀造成存储压力,实时离线可能多份4,计算压力变大:夜间计算窗口可能完不成白天累积的数据数据湖与数仓区别正因为Lambda架构问题居多,我们开始调研数据湖相关技术,数据湖与数仓的区别有很多,我主要从两个维度来分享。 Y" L& s8 ]& w3 k
区别一:计算模型数据湖能够支持增量更新的方式增量流读,但数仓是基于全量或分区覆盖的方式,不支持局部更新区别二:数据管理数据湖基于统计信息,索引管理文件,能够更细粒度的管理数据文件,加速数据入湖或数据在湖上查询,而数仓更多是基于分区管理。 6 L+ q3 F" \4 B: N* O( H
不仅如此,数据湖还具备如快照、时间旅行、结构演进等数仓不具备的特性数据湖基本概念和原理选择hudi的原因是因为其包含了数据湖的多个基本特性,如ACID事物支持、Merge-On-Read、Bulk Load、Incremental Query、Time travel等等;其次,hudi在设计开始就拥有任务自管理功能,包括快照commit、过期快照清理、小文件合并、mor表的定期压缩、rollback、回滚等;最后是因为比较键、Payload抽象,比较键既能应对CDC场景又包括普通消息,payload能够在合并阶段完成包括更新,局部更新等特殊场景。 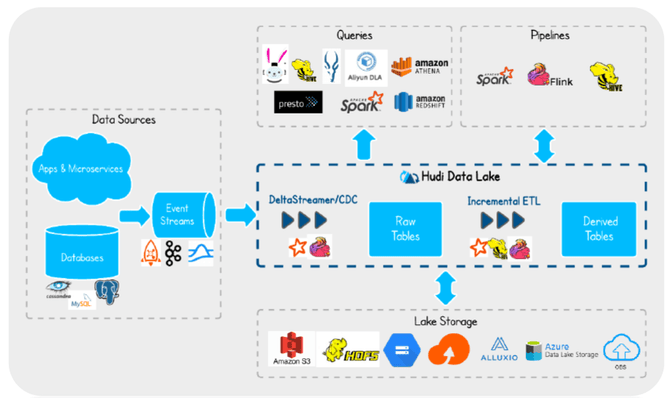 5 L+ K; L$ \, ] 5 L+ K; L$ \, ]
在hudi整体应用架构方面,hudi是介于HDFS或对象存储和查询引擎之间的抽象,自身提供了数据湖的基本功能之外,还包括自带的数据摄入模块,同时在应用架构中还划出了增量流读的过程,为后续构建流式数仓提供了可能性。 P& r- q/ n* B9 N* a- ]( a0 g0 R h
hudi如何进行数据更新?模式一:Copy-On-Write,写时合并,写放大,读优化;模式二:Merge-On-Read,读时合并/定期合并,读放大,写优化;hudi的最大特点是具有索引技术,数据湖索引包括如Bloom/bucket/hbase等,我们可以通过主键索引实现高效局部更新,还可基于索引优化查询。 ! u0 Z' ^" X$ `& w j! b! T
时间抽也是hudi不得不提的一个概念,一个时间轴由三部分组成:Action:COMMITS,CLEANS;State:REQUESTED,INFLIGHT和time时间轴是hudi实现快照流读,回滚不可或缺的一个设计。 1 f/ r$ X1 Z4 A
湖仓一体实践在湖仓一体整体架构上,我们采用了批流一体的统一实时离线链路,并自研了数据集成方案。 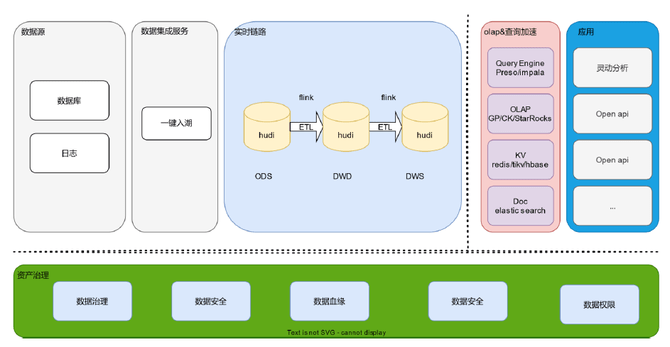 : ^9 G; M+ a C8 E3 y4 `2 S
: ^9 G; M+ a C8 E3 y4 `2 S 目前,我们的湖仓一体现状是:700+核心ODS表入湖;基于ODS清洗任务启动时间提前至:0:05;核心ODS层数据新鲜度由T+1提升至分钟级;完成多个业务线流式数仓场景落地在流式数仓场景上,我们从底层数据、数仓模型到报表全面切到湖仓一体中,支撑用车业务能更及时监控坏账、经营数据。 5 f5 u9 y" c0 J" P
同时,我们还运用局部更新Payload实现了实时关联维度数据打宽在增量统计场景上,我们结合Flink Cumulate窗口实现数据增量统计入hudi在数据湖应用过程中碰到了一些挑战:如何让业务更快的入湖?元数据多引擎多次声明如何解决?入湖的数据脱敏和数据质量怎么做?数据丢失?。 ; E5 T* c7 H3 c
数据集成选型我们有两种方案,即Flink CDC和自研基于MQ。虽然Flink CDC已经很完善了,但是我们内部还是出于数据安全和MQ复用这两点的考虑选择自研。 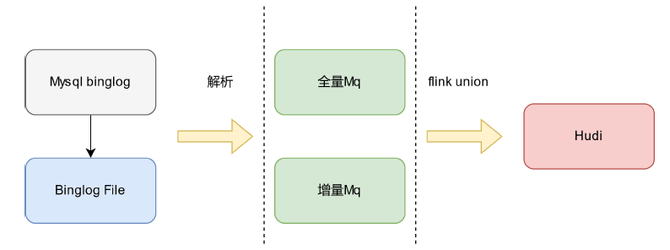 0 Y1 l7 \7 w+ C( t" u
0 Y1 l7 \7 w+ C( t" u 数据集成架构V1的优点和问题:优点是适合中等数据量场景,可实现在线补数(全量、增量)。问题是全量数据参与了入湖Upsert计算,数据量较大时全量集群IO压力大,并行任务数受限。 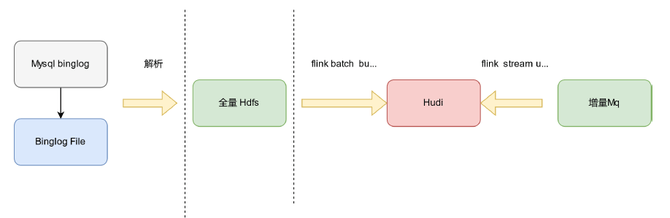 ( S5 B0 D8 o) B1 p ( S5 B0 D8 o) B1 p
数据集成架构V2做出了优化,其更适合超大数据量场景,同时并行多任务。通过优化,我们屏蔽了相关资源申请、Flink同步任务、Hudi参数等细节,实现一键同步功能。 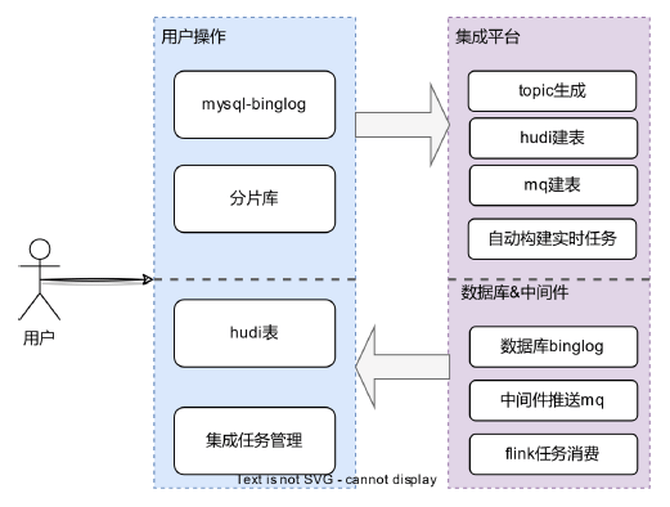 , U) ~- n1 z0 ]/ n/ u& `
, U) ~- n1 z0 ]/ n/ u& ` 下一个挑战是元数据的问题:Flink任务声明Hudi表,开启同步到Hive,Flink流读/批任务需再次重新声明Hudi表;Mq表的声明同样,多次消费多次定义;数据血缘采集困难。 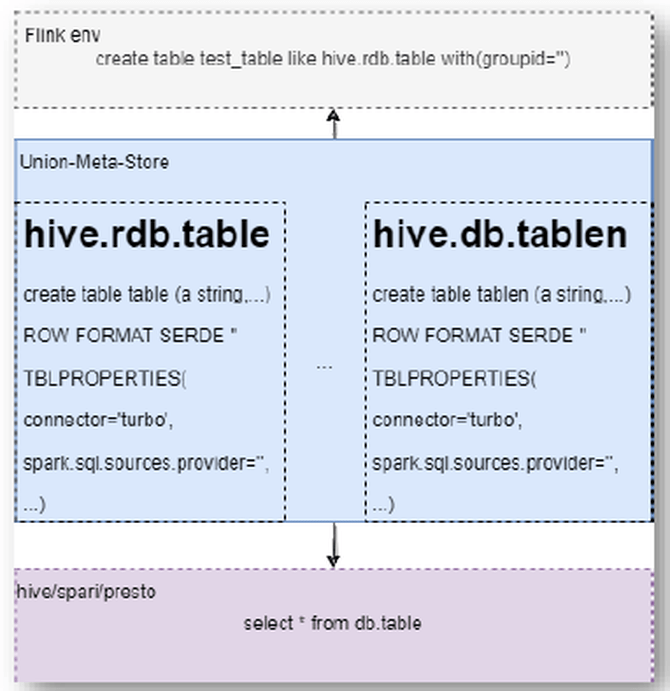 ' W, t" k2 h. ?7 p/ m x
' W, t" k2 h. ?7 p/ m x 我们如何解决上述问题呢?以元数据声明为例,我们针对痛点提供了一套统一元数据方案,具体实现方式是:改造Hive-Connector,使用原生Meta列属性;Flink使用通过like方式修改属性;扩展hive引擎支持通过Hive Sql查询消息队列。
8 l/ g& f w0 w' P 统一元数据之后,实现Flink/Hive/Spark/Presto多引擎共用,一次声明多次使用。  - G6 C0 g; `$ m) `3 o( P& t
- G6 C0 g; `$ m) `3 o( P& t 在数据脱敏方面,如何取样落在MQ中的数据源?我们自研了Flink sql数据预览,基于On yarn Session集群实现,支持多Flink版本,可复用FlinkTaskManager(1小时过期),最快5s内返回结果。
: ? a# J( f6 @ 在预览脱敏方面,我们即席预览数据,通过自定义加密函数进行数据脱敏下一个挑战是数据质量的问题:每日凌晨MQ数据抽样数据时间;批处理前置增加数据质量监控依赖在数据丢失方面,主要有两个代表性的情况,HUDI-4311和HUDI-3912。
8 T. U. j# R0 O5 d7 I 同时,我们对hudi应用过程中还有很多其他的修复给大家分享一些部分hudi使用建议,在提升入湖速度方面,可以增加任务Checkpoint时间间隔,增加相邻两次Checkpoint间隔,减少管理内存大小(Bucket Index),增加Hudi合并内存大小。
( q* p2 r/ D1 N7 v 在提升入湖稳定性方面,增加Flink任务堆外内存的配比(合并阶段,Flink默认为0),设置合理的保留策略避免.hoodie路径下文件过多,关注存储RPC压力情况未来规划针对未来,我们还将不断完善在数据湖上的应用,具体方向包括:提升湖仓易用性,扩大湖仓应用范围和完善湖上分析能力。
5 ~/ c9 P4 _4 @3 v 嘉宾介绍吴祥平,同程旅行数据中心计算集群研发组技术负责人。2012年毕业于浙江海洋大学,热爱Coding、热爱开源,是flink、hudi开源社区贡献者。返回搜狐,查看更多责任编辑:
, q, Q' M& ]5 J' l( z0 x
l+ }' H; }% p w; l
% w0 `' q5 D& d6 {6 Q7 z. \& I9 Y& `2 f, t9 k
- R& Q5 u& V. V5 o& b
| 

