|
3 h' n% n# \6 E 原标题:并发提升20+倍、单节点数万QPS,Apache Doris高并发特性解读随着用户规模的极速扩张,越来越多用户将 Apache Doris 用于构建企业内部的统一分析平台,这一方面需要 Apache Doris 去承担更大业务规模的处理和分析——既包含了更大规模的数据量、也包含了更高的并发承载,而另一方面,也意味着需要应对企业更加多样化的数据分析诉求,从过去的统计报表、即席查询、交互式分析等典型 OLAP 场景,拓展到推荐、风控、标签画像以及 IoT 等更多业务场景中,而数据服务(Data Serving)就是其中具有代表性的一类需求。 8 t- H( {. F7 R& U
Data Serving 通常指的是向用户或企业客户提供数据访问服务,用户使用较为频繁的查询模式一般是按照 Key 查询一行或多行数据,例如:订单详情查询商品详情查询物流状态查询交易详情查询用户信息查询 ! t" N6 O+ s* ?7 [3 X
用户画像属性查询...与面向大规模数据扫描与计算的 Adhoc 不同,Data Serving 在实际业务中通常呈现为高并发的点查询——查询返回的数据量较少、通常只需返回一行或者少量行数据,但对于查询耗时极为敏感、期望在毫秒内返回查询结果,并且面临着超高并发的挑战。 * I/ b; N N% i
在过去面对此类业务需求时,通常采取不同的系统组件分别承载对应的查询访问OLAP 数据库一般是基于列式存储引擎构建,且是针对大数据场景设计的查询框架,通常以数据吞吐量来衡量系统能力,因此在 Data Serving 高并发点查场景的表现往往不及用户预期。
; J! ^& B8 L1 h; u! Y D 基于此,用户一般引入 Apache HBase 等 KV 系统来应对点查询、Redis 作为缓存层来分担高并发带来的系统压力而这样的架构往往比较复杂,存在冗余存储、维护成本高的问题融合统一的分析范式为 Apache Doris 能承载的工作负载带来了挑战,也让我们更加系统化地去思考如何更好地满足用户在此类场景的业务需求。 4 |6 q$ t8 K T
基于以上思考,在即将发布的 2.0 版本中,我们在原有功能基础上引入了一系列面向点查询的优化手段,单节点可达数万 QPS 的超高并发,极大拓宽了适用场景的能力边界# 如何应对高并发查询?一直以来高并发就是 Apache Doris 的优势之一。
& y- f7 P) y/ ]- s5 y 对于高并发查询,其核心在于如何平衡有限的系统资源消耗与并发执行带来的高负载换而言之,需要最大化降低单个 SQL 执行时的 CPU、内存和 IO 开销,其关键在于减少底层数据的 Scan 以及随后的数据计算,其主要优化方式有如下几种:。
; I! e } Y: j. x U3 j. P 分区分桶裁剪Apache Doris 采用两级分区,第一级是 Partition,通常可以将时间作为分区键第二级为 Bucket,通过 Hash 将数据打散至各个节点中,以此提升读取并行度并进一步提高读取吞吐。
# U! z4 M; h! ^* l% w7 e 通过合理地划分区分桶,可以提高查询性能,以下列查询语句为例:select* fromuser_table whereid= 5122andcreate_date = 2022-01-01用户以create_time 6 r6 H( H% q u6 U9 p0 d3 G
作为分区键、ID 作为分桶键,并设置了 10 个 Bucket, 经过分区分桶裁剪后可快速过滤非必要的分区数据,最终只需读取极少数据,比如 1 个分区的 1 个 Bucket 即可快速定位到查询结果,最大限度减少了数据的扫描量、降低了单个查询的延时。
; R9 \; s& z# a* i% q6 h _5 K 索引除了分区分桶裁剪, Doris 还提供了丰富的索引结构来加速数据的读取和过滤索引的类型大体可以分为智能索引和二级索引两种,其中智能索引是在 Doris 数据写入时自动生成的,无需用户干预智能索引包括前缀索引和 ZoneMap 索引两类:。 % Y0 S- q4 R; w4 X* g
前缀稀疏索引(Sorted Index) 是建立在排序结构上的一种索引Doris 存储在文件中的数据,是按照排序列有序存储的,Doris 会在排序数据上每 1024 行创建一个稀疏索引项索引的 Key 即当前这 1024 行中第一行的前缀排序列的值,当用户的查询条件包含这些排序列时,可以通过前缀稀疏索引快速定位到起始行。
* V/ u! u! N% {) Q& z0 O" } ZoneMap 索引 是建立在 Segment 和 Page 级别的索引对于 Page 中的每一列,都会记录在这个 Page 中的最大值和最小值,同样,在 Segment 级别也会对每一列的最大值和最小值进行记录。
) v) V, { h! _$ R* v+ ] 这样当进行等值或范围查询时,可以通过 MinMax 索引快速过滤掉不需要读取的行二级索引是需要用手动创建的索引,包括 Bloom Filter 索引、Bitmap 索引,以及 2.0 版本新增的 Inverted 倒排索引和 NGram Bloom Filter 索引,在此不细述,可从官网文档先行了解,后续将有系列文章进行解读。 9 b+ K6 e: N {! ~8 A" `
官网文档:倒排索引: https://doris.apache.org/zh-CN/docs/dev/data-table/index/inverted-indexNGram BloomFilter 索引: https://doris.apache.org/zh-CN/docs/dev/data-table/index/ngram-bloomfilter-index
# a; b" H3 D. D! n: B0 w; i* q/ n 我们以下列查询语句为例:select* fromuser_table whereid> 10andid< 1024假设按照 ID 作为建表时指定的 Key, 那么在 Memtable 以及磁盘上按照 ID 有序的方式进行组织,查询时如果过滤条件包含前缀字段时,则可以使用前缀索引快速过滤。
- B! _. g2 n2 Q7 n f( H$ T Key 查询条件在存储层会被划分为多个 Range,按照前缀索引做二分查找获取到对应的行号范围,由于前缀索引是稀疏的,所以只能大致定位出行的范围随后过一遍 ZoneMap、Bloom Filter、Bitmap 等索引,进一步缩小需要 Scan 的行数。
* h p; F8 K5 S5 u" I 通过索引,大大减少了需要扫描的行数,减少 CPU 和 IO 的压力,整体大幅提升了系统的并发能力物化视图物化视图是一种典型的空间换时间的思路,其本质是根据预定义的 SQL 分析语句执⾏预计算,并将计算结果持久化到另一张对用户透明但有实际存储的表中。
* i* G% J5 p1 @4 m 在需要同时查询聚合数据和明细数据以及匹配不同前缀索引的场景,命中物化视图时可以获得更快的查询相应,同时也避免了大量的现场计算,因此可以提高性能表现并降低资源消耗// 对于聚合操作, 直接读物化视图预聚合的列 。 ( H: x3 C; q2 l: F- q. m9 o6 M
creatematerializedviewstore_amt asselectstore_id, sum(sale_amt) fromsales_records groupbystore_id; SELECT
' } m! B- s& m k store_id, sum(sale_amt) FROMsales_records GROUPBYstore_id; // 对于查询, k3满足物化视图前缀列条件, 走物化视图加速查询 CREATEMATERIALIZED
6 d! Q1 i# T+ } E2 b3 T1 ~ VIEWmv_1 asSELECTk3, k2, k1 FROMtableA ORDERBYk3; selectk1, k2, k3 fromtableA wherek3= 3; Runtime Filter
9 i+ q& o) f) m3 ^% d$ J- K' f 除了前文提到的用索引来加速过滤查询的数据, Doris 中还额外加入了动态过滤机制,即 Runtime Filter在多表关联查询时,我们通常将右表称为 BuildTable、左表称为 ProbeTable,左表的数据量会大于右表的数据。
) a0 [( a2 @# S% l+ M0 W- [; D, y9 ] 在实现上,会首先读取右表的数据,在内存中构建一个 HashTable(Build)之后开始读取左表的每一行数据,并在 HashTable 中进行连接匹配,来返回符合连接条件的数据(Probe)而 Runtime Filter 是在右表构建 HashTable 的同时,为连接列生成一个过滤结构,可以是 Min/Max、IN 等过滤条件。 # M# r# {* n6 M3 ~+ D* b& q
之后把这个过滤列结构下推给左表这样一来,左表就可以利用这个过滤结构,对数据进行过滤,从而减少 Probe 节点需要传输和比对的数据量在大多数 Join 场景中,Runtime Filter 可以实现节点的自动穿透,将 Filter 穿透下推到最底层的扫描节点或者分布式 Shuffle Join 中。
: m q. K$ L. k5 T9 q7 a) W 大多数的关联查询 Runtime Filter 都可以起到大幅减少数据读取的效果,从而加速整个查询的速度TOPN 优化技术在数据库中查询最大或最小几条数据的应用场景非常广泛,比如查询满足某种条件的时间最近 100 条数据、查询价格最高或者最低的几个商品等,此类查询的性能对于实时分析非常重要。
+ l5 b9 X3 A' x4 `* g( r# s# h 在 Doris 中引入了 TOPN 优化来解决大数据场景下较高的 IO、CPU、内存资源消耗:首先从 Scanner 层读取排序字段和查询字段,利用堆排序保留 TOPN 条数据,实时更新当前已知的最大或最小的数据范围, 并动态下推至 Scanner 7 h' W, Q% @2 o' I& V
Scanner 层根据范围条件,利用索引等加速跳过文件和数据块,大幅减少读取的数据量在宽表中用户通常需要查询字段数较多, 在 TOPN 场景实际有效的数据仅 N 条, 通过将读取拆分成两阶段, 第一阶段根据少量的排序列、条件列来定位行号并排序,第二阶段根据排序后并取 TOPN 的结果得到行号反向查询数据,这样可以大大降低 Scan 的开销。
7 R! q+ \& I6 R- ~- b6 ]* J% ^ 通过以上一系列优化手段,可以将不必要的数据剪枝掉,减少读取、排序的数据量,显著降低系统 IO、CPU 以及内存资源消耗此外,还可以利用包括 SQL Cache、Partition Ca che 在内的缓存机制以及 Join 优化手段来进一步提升并发,由于篇幅原因不在此详述。 6 k M- E+ \. Q2 ]2 I. i F {
# Apache Doris 2.0 新特性揭秘通过上一段中所介绍的内容,Apache Doris 实现了单节点上千 QPS 的并发支持但在一些超高并发要求(例如数万 QPS)的 Data Serving 场景中,仍然存在瓶颈:。
1 p' K4 u0 A4 M: r2 m6 i- Q' M d 列式存储引擎对于行级数据的读取不友好,宽表模型上列存格式将大大放大随机读取 IO;OLAP 数据库的执行引擎和查询优化器对于某些简单的查询(如点查询)来说太重,需要在查询规划中规划短路径来处理此类查询; S+ Z6 ~3 r) q6 c# C
SQL 请求的接入以及查询计划的解析与生成由 FE 模块负责,使用的是 Java 语言,在高并发场景下解析和生成大量的查询执行计划会导致高 CPU 开销;……带着以上问题,Apache Doris 在分别从降低 SQL 内存 IO 开销、提升点查执行效率以及降低 SQL 解析开销这三个设计点出发,进行一系列优化。
7 K5 f& @6 r0 i1 h: [ 行式存储格式(Row Store Format)与列式存储格式不同,行式存储格式在数据服务场景会更加友好,数据按行存储、应对单次检索整行数据时效率更高,可以极大减少磁盘访问次数因此在 Apache Doris 2.0 版本中,我们引入了行式存储格式,将行存编码后存在单独的一列中,通过额外的空间来存储。 ) \! v- n' ?! a/ f5 B( J* b
用户可以在建表语句的 Property 中指定如下属性来开启行存:"store_row_column" = "true" 我们选择以 JSONB 作为行存的编码格式,主要出于以下考虑:Schema 变更灵活:随着数据的变化、变更,表的 Schema 也可能发生相应变化。
! v! k0 c' `$ |% p4 t- G 行存储格式提供灵活性以处理这些变化是很重要的,例如用户删减字段、修改字段类型,数据变更需要及时同步到行存中通过使用 JSONB 作为编码方式,将列作为 JSONB 的字段进行编码, 可以非常方便地进行字段扩展以及更改属性。 2 f" l: s! C- A! J* ~
性能更高:在行存储格式中访问行可以比在列存储格式中访问行更快,因为数据存储在单个行中这可以在高并发场景下显著减少磁盘访问开销此外,通过将每个列 ID 映射到 JSONB其对应的值,可以实现对个别列的快速访问。 / V+ G9 N# d' F/ B5 B
存储空间:将 JSONB 作为行存储格式的编解码器也可以帮助减少磁盘存储成本紧凑的二进制格式可以减少存储在磁盘上的数据总大小,使其更具成本效益使用 JSONB 编解码行存储格式,可以帮助解决高并发场景下面临的性能和存储问题。
1 w6 d9 d! P% s3 ^/ v% _ 行存在存储引擎中会作为一个隐藏列(DORIS_ROW_STORE_COL )来进行存储,在 Memtable Flush 时,将各个列按照 JSONB 进行编码并缓存到这个隐藏列里在数据读取时, 通过该隐藏列的 Column ID 来定位该列, 通过其行号定位到某一具体的行,并反序列化各列。
! v' v2 N; T1 }7 g! l6 C 相关PR:https://github.com/apache/doris/pull/15491点查询短路径优化(Short-Circuit)通常情况下,一条 SQL 语句的执行需要经过三个步骤:首先通过 SQL Parser 解析语句,生成抽象语法树(AST),随后通过 Query Optimizer 生成可执行计划(Plan),最终通过执行该计划得到计算结果。
0 J: R9 g4 Z* _3 p O" F 对于大数据量下的复杂查询,经由查询优化器生成的执行计划无疑具有更高效的执行效果,但对于低延时和高并发要求的点查询,则不适宜走整个查询优化器的优化流程,会带来不必要的额外开销为了解决这个问题,我们实现了点查询的短路径优化,绕过查询优化器以及 PlanFragment 来简化 SQL 执行流程,直接使用快速高效的读路径来检索所需的数据。 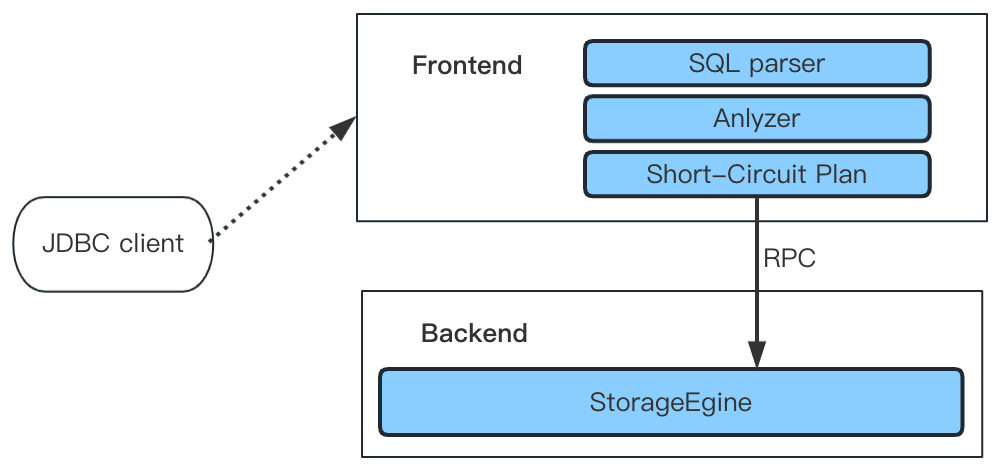 ' u1 i5 W; ~; J% k ' u1 i5 W; ~; J% k
当查询被 FE 接收后,它将由规划器生成适当的 Short-Circuit Plan 作为点查询的物理计划该 Plan 非常轻量级,不需要任何等效变换、逻辑优化或物理优化,仅对 AST 树进行一些基本分析、构建相应的固定计划并减少优化器的开销。
# F# Z" M+ l6 M6 R* W. g 对于简单的主键点查询,如select * from tbl where pk1 = 123 and pk2 = 456 ,因为其只涉及单个 Tablet,因此可以使用轻量的 RPC 接口来直接与 StorageEngine 进行交互,以此避免生成复杂的Fragment Plan 并消除了在 MPP 查询框架下执行调度的性能开销。 # C3 H3 ^) ~$ P( o( n$ p
RPC 接口的详细信息如下:message PTabletKeyLookupRequest { required int64 tablet_id = 1; repeated KeyTuple key_tuples = 2; " Z' V& d" S% S; q# _
optional Deor desc_tbl = 4; optional ExprList output_expr = 5; } message PTabletKeyLookupResponse { required PStatus status = 1;
7 P0 |5 v% y; Q. ~ optional bytes row_batch = 5; optional bool empty_batch = 6; } rpc tablet_fetch_data(PTabletKeyLookupRequest) returns (PTabletKeyLookupResponse);
0 D4 q" d) S8 K# V 以上 tablet_id 是从主键条件列计算得出的,key_tuples 是主键的字符串格式,在上面的示例中,key_tuples 类似于 [123, 456],在 BE 收到请求后key_tuples 3 \" u s8 T' c E9 j, H
将被编码为主键存储格式,并根据主键索引来识别 Key 在 Segment File 中的行号,并查看对应的行是否在delete bitmap 中,如果存在则返回其行号,否则返回NotFound 然后使用该行号直对。
6 H# u+ i0 J6 e __DORIS_ROW_STORE_COL__ 列进行点查询,因此我们只需在该列中定位一行并获取 JSONB 格式的原始值,并对其进行反序列化作为后续输出函数计算的值相关PR:https://github.com/apache/doris/pull/15491。 7 K& E) l0 w" w/ |) a2 p5 V$ J7 \
预处理语句优化(PreparedStatement)高并发查询中的 CPU 开销可以部分归因于 FE 层分析和解析 SQL 的 CPU 计算,为了解决这个问题,我们在 FE 端提供了与 MySQL 协议完全兼容的预处理语句(Prepared Statement)。
3 F" S* t) p% D' H' @% J 当 CPU 成为主键点查的性能瓶颈时,Prepared Statement 可以有效发挥作用,实现 4 倍以上的性能提升。 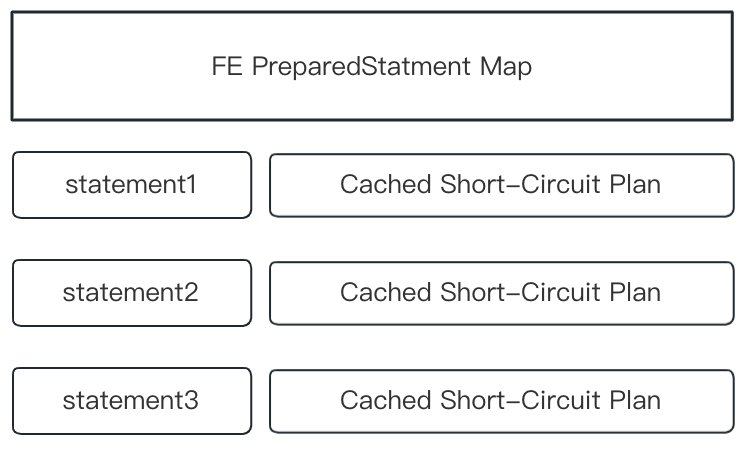 9 a! F) w: [: H. j' w
9 a! F) w: [: H. j' w Prepared Statement 的工作原理是通过在 Session 内存 HashMap 中缓存预先计算好的 SQL 和表达式,在后续查询时直接复用缓存对象即可Prepared Statement 使用 。 8 Y( Y0 H& }6 p; b" z$ q" b/ |) U; f
MySQL 二进制协议(https://dev.mysql.com/doc/dev/mysqlserver/latest/page_protocol_binary_resultset.html#sect_protocol_binary_resultset_row % Z5 p Z. ]" j; O0 l- m5 B
)作为传输协议该协议在文件mysql_row_buffer.[h|cpp] 中实现,符合标准 MySQL 二进制编码, 通过该协议客户端例如 JDBC Client, 第一阶段发送PREPARE MySQL Command 将预编译语句发送给 FE 并由 FE 解析、Analyze 该语句并缓存到上图的 HashMap 中,接着客户端通过。
8 C. D2 N! T6 X) T, Z. d, K EXECUTE MySQL Command 将占位符替换并编码成二进制的格式发送给 FE, 此时 FE 按照 MySQL 协议反序列化后得到占位符中的值,生成对应的查询条件。 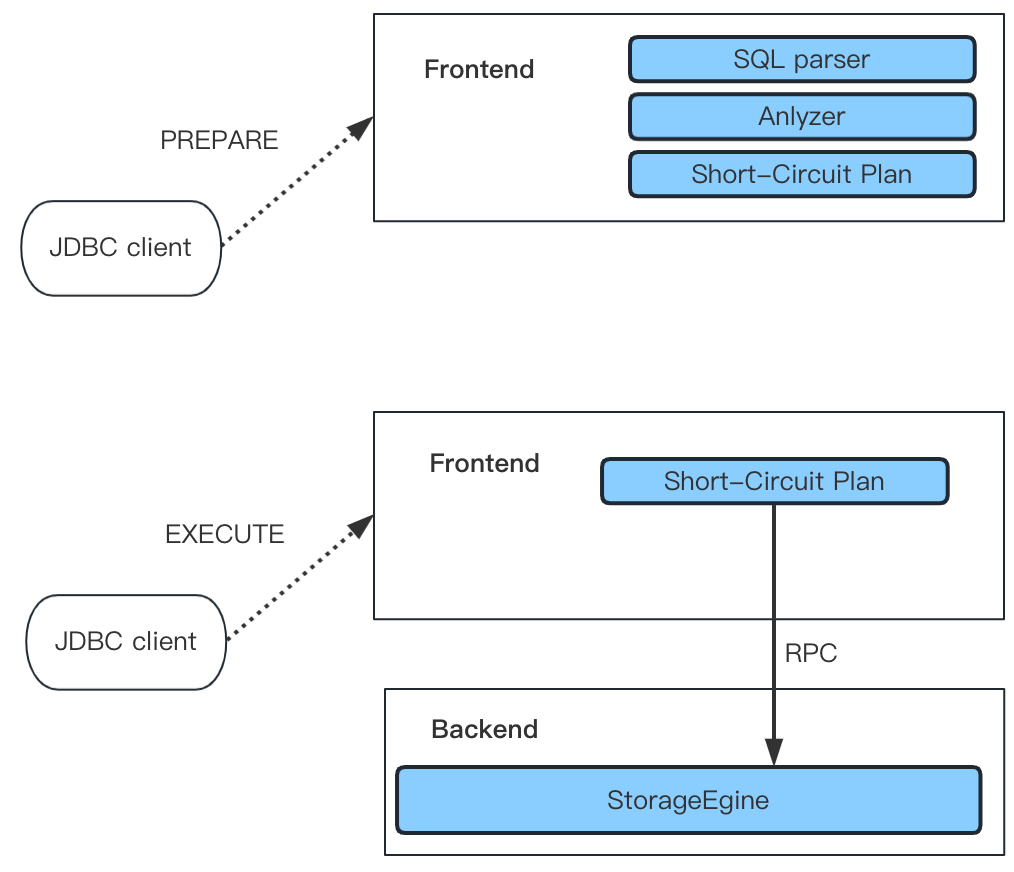 ; z5 z" b' d" d1 v1 q! I- |6 N ; z5 z" b' d" d1 v1 q! I- |6 N
除了在 FE 缓存 Statement,我们还需要在 BE 中缓存被重复使用的结构,包括预先分配的计算 Block,查询描述符和输出表达式,由于这些结构在序列化和反序列化时会造成 CPU 热点, 所以需要将这些结构缓存下来。
- @9 Z2 n; }* b2 e" K7 Z! T 对于每个查询的 PreparedStatement,都会附带一个名为 CacheID 的 UUID当 BE 执行点查询时,根据相关的 CacheID 找到对应的复用类, 并在 BE 中表达式计算、执行时重复使用上述结构。 & j& C, c' m. j2 `* T4 f
下面是在 JDBC 中使用 PreparedStatement 的示例:1. 设置 JDBC URL 并在 Server 端开启 PreparedStatementurl = jdbc:mysql://127.0.0.1:9030/ycsb?useServerPrepStmts=true
5 d6 w; ~ y w 2. 使用 Prepared Statement// use`?`forplacement holders, readStatement should be reused PreparedStatement readStatement = conn.prepareStatement(
, f$ t |1 d+ w/ p i+ t( ]$ S "select * from tbl_point_query where key = ?"); ... readStatement.setInt(1234); ResultSet resultSet = readStatement.executeQuery;
4 h8 j+ i$ r& I! E4 x" ] ... readStatement.setInt(1235); resultSet = readStatement.executeQuery; ... 相关 PR:https://github.com/apache/doris/pull/15491
* ]5 q: D/ |! K) t1 r 行存缓存Doris 中有针对 Page 级别的 Cache,每个 Page 中存的是某一列的数据,所以 Page Cache 是针对列的缓存对于前面提到的行存,一行里包括了多列数据,缓存可能被大查询给刷掉,为了增加行缓存命中率,就需要单独引入行存缓存(Row Cache)。
4 B/ d6 I% J7 K2 x 行存 Cache 复用了 Doris 中的 LRU Cache 机制, 启动时会初始化一个内存阈值, 当超过内存阈值后会淘汰掉陈旧的缓存行对于一条主键查询语句,在存储层上命中行缓存和不命中行缓存可能有数十倍的性能差距(磁盘 IO 与内存的访问差距),。
" E# Y4 o! L3 D1 ^6 F* B& r 因此行缓存的引入可以极大提升点查询的性能,特别是缓存命中高的场景下开启行存缓存可以在 BE 中设置以下配置项来开启:disable_storage_row_cache=false //是否开启行缓存, 默认不开启 。
) b- ~3 x- n2 m m row_cache_mem_limit=20% // 指定row cache占用内存的百分比, 默认 20%内存 相关 PR:https://github.com/apache/doris/pull/15491
W1 \/ z+ J" J1 V \- V! U # Benchmark基于以上一系列优化,帮助 Apache Doris 在 Data Serving 场景的性能得到进一步提升我们基于 Yahoo! Cloud Serving Benchmark (YCSB)标准性能测试工具进行了基准测试,其中环境配置与数据规模如下:。
$ s9 V f, H( T/ y( ~7 N+ w& F 机器环境:单台 16 Core 64G 内存 4*1T 硬盘的云服务器集群规模:1 FE + 3 BE数据规模:一共 1 亿条数据,平均每行在 1K 左右,测试前进行了预热对应测试表结构与查询语句如下:。 ; K4 D/ ~" \+ D
// 建表语句如下: CREATETABLE`usertable`( `YCSB_KEY`varchar( 255) NULL, `FIELD0`textNULL, `FIELD1`textNULL, 2 W! o# v6 o9 ~* }( e" {
`FIELD2`textNULL, `FIELD3`textNULL, `FIELD4`textNULL, `FIELD5`textNULL, `FIELD6`textNULL, `FIELD7`text
% w3 Z: O5 y5 q NULL, `FIELD8`textNULL, `FIELD9`textNULL) ENGINE=OLAP UNIQUEKEY( `YCSB_KEY`) COMMENTOLAPDISTRIBUTEDBY % I# v! R' G# g- G' p+ C
HASH( `YCSB_KEY`) BUCKETS 16PROPERTIES ( "replication_allocation"= "tag.location.default: 1", "in_memory" / m( F8 N7 c; ~8 I8 R6 ^) D: W
= "false", "persistent"= "false", "storage_format"= "V2", "enable_unique_key_merge_on_write"= "true", # w6 }$ V) P4 I9 |% }: J& k
"light_schema_change"= "true", "store_row_column"= "true", "disable_auto_compaction"= "false"); // 查询语句如下:
9 i D" y/ m9 W( M; }6 a SELECT* fromusertable WHEREYCSB_KEY = ? 开启优化(即同时开启行存、点查短路径以及 PreparedStatement)与未开启的测试结果如下:开启以上优化项后平均
& \! l4 }2 B2 r& _ k2 M" I/ e 查询耗时降低了 96%,99 分位的查询耗时仅之前的 1/28,QPS 并发从 1400 增至 3w、提升了超过 20 倍,整体性能表现和并发承载实现数据量级的飞跃!# 最佳实践需要注意的是,在当前阶段实现的点查询优化均是在 Unique Key 主键模型进行的,同时需要开启 Merge-on-Write 以及 Light Schema Change 后使用,以下是点查询场景的建表语句示例:
" y, I5 g: M9 s- N; Z+ F2 T CREATE TABLE `usertable` ( `USER_KEY` BIGINT NULL, `FIELD0` text NULL, `FIELD1` text NULL, `FIELD2` text NULL, - d" T/ r7 K8 ]) S5 U7 _
`FIELD3` text NULL ) ENGINE= OLAP UNIQUE KEY(`USER_KEY`)COMMENT OLAP DISTRIBUTED BY HASH(`USER_KEY`)BUCKETS 16
& T+ h9 w$ S' @, [% ?! A4 y PROPERTIES( "enable_unique_key_merge_on_write"= "true", "light_schema_change"= "true", "store_row_column" ( Y$ @5 C X3 F2 q% Z
= "true", ) ; 注意:开启 light_schema_change 来支持 JSONB 行存编码 ColumnID开启 store_row_column 来存储行存格式完成建表操作后,类似如下基于主键的点查 SQL 可通过行式存储格式和短路径执行得到性能的大幅提升: 7 I; s% [4 F6 W$ J
select * from usertable where USER_KEY = xxx; 与此同时,可以通过 JDBC 中的 Prepared Statement 来进一步提升点查询性能如果有充足的内存, 还可以在 BE 配置文件中开启行存 Cache,上文中均已给出使用示例,在此不再赘述。
7 G5 a7 W0 u% ], F1 A # 总结通过引入行式存储格式、点查询短路径优化、预处理语句以及行存缓存,Apache Doris 实现了单节点上万 QPS 的超高并发,实现了数十倍的性能飞跃而随着集群规模的横向拓展、机器配置的提升,Apache Doris 还可以利用硬件资源实现计算加速,自身的 MPP 架构也具备横向线性拓展的能力。
3 r2 w6 z: W o$ H 因此 Apache Doris 真正具备了在一套架构下同时满足高吞吐的 OLAP 分析和高并发的 Data Serving 在线服务的能力,大大简化了混合工作负载下的技术架构,为用户提供了多场景下的统一分析体验
5 y* M* r" Y( {- u 作者介绍:李航宇,Apache Doris Contributor,SelectDB 半结构化研发工程师微软开源Visual ChatGPT,7天斩获2.2万stars Linux内核、LLVM、GCC均已支持龙芯LoongArch架构 JDK 20 / Java 20正式GA 。
# g0 b8 |* N( n1 r. _/ E 这里有最新开源资讯、软件更新、技术干货等内容点这里 ↓↓↓ 记得 关注✔ 标星⭐ 哦返回搜狐,查看更多责任编辑:
5 b7 W8 A0 ^. K3 a
: K$ `# L5 C3 ~2 H
4 |# \; h5 O7 F( P% Y# W4 K4 P5 N" y
, T4 w' T9 @+ B+ o, F" V3 ? H | 

