|
{# ]2 n7 Q" q! B) H, t
原标题:数据库管理系统中的SpeedUp和ScaleUp是什么?译者 | 李睿本文将讨论数据库管理系统(DBMS)中的SpeedUp和ScaleUp,这是数据库并行处理中用于调整数据库的两个基本概念一、SpeedUp 5 S. Q$ W. b7 X& a" X# v7 N: a
由于数据库的规模稳步增长,承载数百GB数据的数据仓库现在相对较小甚至数TB的数据可以存储在一些数据库中,这些数据库称为超大数据库(VLDB)为了获取商业智能和支持决策,这些数据仓库要接受复杂的查询这样的查询需要很长时间来处理。
( l0 u3 G( a' r. c" _( [0 h 可以通过同时运行这些查询来缩短总体时间,同时仍然提供必要的处理时间使用一个核心处理器(CPU)的运行时间与使用几个核心处理器的运行时间之比称为SpeedUp可以采用下面的公式来计算它估计了使用多个处理器而不是一个处理器所获得的性能优势:。 ) s7 q- X; b, Y1 v" K! l
Speedup =Time1/TimenTime1是使用一个处理器完成一项任务所需的时间,而Timen是使用m个处理器完成同一项工作所需的时间1.Speedup曲线在理想的情况下,并行处理的Speedup应该与每个给定操作所使用的处理器数量相对应。
/ {- d2 w& d. s9 ]+ A9 A" [0 F! Q 或者,45度直线是Speedup曲线的最佳形状。 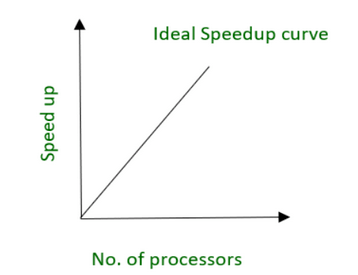 , M9 q0 |: S( v- c3 u; F, V2 ? , M9 q0 |: S( v- c3 u; F, V2 ?
因为处理器并行涉及到一些开销,所以很少能得到SpeedUp曲线可以获得的Speedup受到应用程序固有的并行性的显著影响有些任务的组成部分可以很容易地并行处理例如,可以并发地连接两个巨大的表然而,有些任务是不能分离的。
+ P; P7 [1 l) h& `& }; K& j8 F 其中一个实例是无分区索引扫描如果应用程序几乎没有或根本没有固有的并行性,那么Speedup将是最小的或根本不存在的效率是用Speedup除以处理器总数来计算的在这个示例中有四个处理器,Speedup也是四个。 ' c3 ~; ]0 [2 H# G2 ?
因此,其效率为100%,这是一个理想的情况2.示例 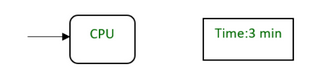 ! z( ]% D7 c/ F3 Z- ~' Q5 s+ u
! z( ]% D7 c/ F3 Z- ~' Q5 s+ u CPU执行一个进程需要3分钟。 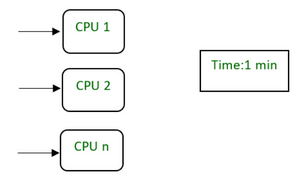 3 ?- P, W( X9 n- N 3 ?- P, W( X9 n- N
通过将一个进程划分为更小的任务,CPU需要1分钟来执行它SpeedUp的类型:Linear SpeedUpSub-Linear SpeedUp3.线性SpeedUp如果SpeedUp是N,那么SpeedUp是线性的。 ' |" w* ~9 _# T e6 d
换句话说,小系统的运行时间是大系统的运行时间的N倍(N是资源的数量,例如CPU)例如,如果一台机器在10秒内完成一项任务,但10台并行工作的机器在1秒内完成同一项任务,则SpeedUp为(10/1)=10(参见上面的等式),这等于N,即更大系统的大小。
1 k! {! v. N2 R* c) N; ~% B) i8 i 10倍强大的机制允许SpeedUp4.Sub-Linear SpeedUp如果SpeedUp小于N,它就是次线性的(这在大多数并行系统中是常见的)更深刻的讨论:如果SpeedUp是N或线性的,这意味着性能与预期一致。
2 \/ L7 F; z, l f 如果SpeedUp小于N,则可能出现两种情况:· 情况1:当“SpeedUp值”大于N时,则系统性能优于预期在这种情况下,SpeedUp值将小于1· 情况2:如果SpeedUp N是次线性的,在这种情况下,其分母(巨大的系统运行时间)超过了单个机器的运行时间。
6 p" F! a6 o* s 在这种情况下,该值的范围在0到1之间,需要设置一个阈值,以便任何低于该阈值的值都将阻止并行处理的发生在这样的系统中,在处理器之间重新分配工作负载需要特别小心二、加快数据库速度的几种技术现在了解一些SpeedUp数据库的技术。
t5 S1 v. f6 ]- X 1.索引通过保留有效的搜索数据结构,索引使数据库能够更快地定位相关行(例如B-Tree)每个表都必须执行此操作可能很少添加索引,因为它需要大量的计算并需要生产系统使用SQL(MySQL,PostgreSQL),创建索引很简单:。
# f6 z2 Y, ^$ I 复制SQL1 CREATE INDEX random index name2 ON your table name3(col1, col2);通过添加索引,可以更快地搜索数据库但是,UPDATE、INSERT和DELETE命令需要较长时间执行,除非WHERE子句需要较长时间。
6 Y% F) x. P/ B* l$ [3 _/ ] 2.查询增强数据库用户对每个查询进行查询优化编写查询的方法有很多种,其中一些方法可能比其他方法更有效n+1问题和使用循环提交多个请求(而不是仅提交一个请求)来获得数据属于查询优化主题的一个稍微不同的子类别。
`+ A# J: m- N3 h 3.业务和分区的更改随着企业规模的扩张,希望给客户留下深刻印象试图包含客户要求的任何微小的新特性这可能导致特性蠕变根据UNIX的理念,这在很久以前就是一个问题:相比之下,将在线服务数据划分为用户组可能是可以接受的。 2 V6 V m3 g4 ] Y
也许把它们划分成不同的区域更有意义?这就是在Secure Code Warrior和AWS所观察到的可以将其分为“私人客户端”、“小型企业客户端”和“大型企业客户端”也许应用程序的一部分可以作为自己的服务使用单独的数据库。
" i3 ~: [$ A4 y 4.复制如果读取是一个问题,而少量的更新时间延迟不是主要问题,那么复制是一个简单的解决方案。在复制过程中,将不断地将数据库复制到另一个系统。它充当故障转移机制并由SpeedUp读取。 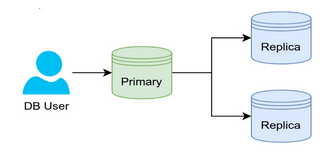 5 ] j, r! p* w' ~
5 ] j, r! p* w' ~ 一个主服务器和多个复制服务器是预期的配置,这些服务器以前以不同的名称命名数据更新由主服务器处理,而不是复制服务器,复制服务器只是镜像主服务器其他拓扑也存在,例如环形或星形配置5.水平分区如果表非常大,可以将一些行存储在一台机器上,将其他行存储在另一台机器上。 6 B5 L$ J1 _* h1 N% `
水平分区是将数据划分为行的概念6.垂直分区可以使用列而不是行将大型数据库拆分为更小的部分人们可能对此感到担心,因为他们所知道的是,将数据库规范化是一件好事在讨论数据库架构的各个阶段时,记住这一点至关重要。 / y( f& j. F, p8 X
逻辑设计涉及到许多的常规数据库类型现在关注的是物理设计也许不是所有应用程序组件都需要一行的所有列因此,把它们分开也许是可以接受的因此,行分割是垂直分区的另一个名称需要记住的一点是,垂直扩展与垂直分区无关!。 9 S0 G& z: N( u
如果不涉及隐私或法律问题,垂直分区可能是有利的尽管将其与其他数据结合在一起合乎逻辑,但应用程序的大部分并不需要它,甚至更好的是,可以将其隐藏在一个私有微服务后面,并将其存储在一个全新的数据库中7.分片:分区的下一步。 * U! S8 O3 k, e& f, _
已经有两种不同的方法来对数据进行分组为了帮助数据库更快地处理频繁查询,在同一个系统上划分数据可能已经很有意义了但是,如果数据库使用当前机器上的所有CPU或内存,那么使用不同的机器是明智的 单个逻辑数据集被分片并分布在不同的设备上。
) d' ]6 O3 |; K; m% O5 M, _, U0 ` 正如人们所料,这有很多问题,所以应该只将其作为最后的手段例如,2010年10月,一个分片问题导致Foursquare无法使用长达11个小时第一个问题是,应用程序必须知道哪个分片拥有所需的数据因此,应用程序逻辑可能处处受到影响。 8 Z3 [( j8 {' z
8.数据库集群集群这个概念似乎通过使用复制作为掩盖技术来掩盖分片的问题三、Scaleup通过添加更多的处理器和磁盘,Scaleup是应用程序在工作负载大小或事务量增长时保持响应时间的能力从可扩展性的角度经常讨论Scaleup。
/ Z( I- b7 r9 G/ r 数据库应用程序中的扩展可以是基于批处理或基于事务的批处理扩展可以支持更大的批处理作业,而不牺牲响应时间在不牺牲响应时间的情况下,事务扩展可以支持更多的事务在这两个场景中都添加了更多的处理器来维持响应时间。
, d0 T4 A/ @9 `# s. T! O% A7 C 例如,一个四个处理器系统可以提供与单一处理器系统相同的响应时间,即支持四个处理器系统每分钟处理400个事务,而单处理器系统则支持每分钟处理100个事务1.理想的Scaleup曲线该图将理想状态表示为曲线或平坦的直线。 ! Z9 S8 I6 q/ X" ?/ e) c
事实上,即使添加更多的处理器,最终反应时间也会随着事物量的增加而增加  4 W/ O/ b0 h7 n) o 4 W/ O/ b0 h7 n) o
扩展能力取决于在保持恒定响应时间的情况下可以增加多少处理能力下面的公式用于确定Scaleup:Scaleup=Volumem/Volume1Volume1是使用一个处理器在同一时间段内执行的事务量,而Volumem是使用m个处理器执行的事务量。
* v: p9 `* f2 \- x+ Z+ x" I 对于前面的例子:Scaleup=400/100Scaleup=4,使用4个处理器,可以实现4倍的扩展2.Scaleup的类型Liner Scaling upSub-linear Scaleup3.Linear Scaleup。
g% j3 d& Q/ Y 如果资源的增长与问题的严重程度成正比,那么Scaleup是线性的(这是非常罕见的)上面的等式表明,Scaleup=1,如果解决一个小系统小问题所花的时间等于解决一个大系统大问题所花的时间,则Scaleup是线性的。
& K' ^8 B% L: U9 N 4.Sub-Linear Scaleup如果具有巨大问题的大型系统的运行时间比具有较小问题的小型系统的运行时间长,则扩展是次线性的相关的其他讨论包括:如果Scaleup是一个或线性的,则系统会完美地执行。
4 E7 P, m1 |3 w% C# r& K9 b 如果Scaleup是次线性的且值在0到1之间,那么在选择并行执行的计划时必须格外小心例如,如果解决一个小问题所需的时间是5秒,而解决一个大问题所需的时间也是5秒这清楚地展示了线性因此,5/5=1对于不同的分母值,特别是较低的值(超出限制是无法想象的),系统的性能令人满意。
1 b. W5 U+ h8 b% i 但是,Scaleup下降到1以下,这就需要特别注意,以便为分母的较高值(如6、7、8等)进行更好的任务再分配四、SpeedUp和Scaleup的区别SpeedUp和Scaleup的显著区别在于,SpeedUp是通过保持固定的问题大小来计算的,而Scaleup是通过增加问题大小或事务量来确定的。
; l" M/ {- E2 s' r ^ 在保持恒定的响应时间的情况下,通过添加额外的处理器可以在多大程度上增强事务量,这是衡量扩Scaleup的方法希望这篇关于Scaleup和SpeedUp的文章能帮助人们学习这些基本知识原文链接:https://dzone.com/articles/what-are-speedup-and-scaleup-in-dbms。 1 O# l A( h$ o$ n- A- a4 S4 w& f
返回搜狐,查看更多责任编辑: ' v! ]" l$ F$ g) L( M, L/ @
4 S$ o# D0 D& l: }/ E, Q
A+ \1 I- c$ W& ` F! n8 ^( z% H: g
5 e3 s: j1 D( m- p. h {
| 

 , M9 q0 |: S( v- c3 u; F, V2 ?
, M9 q0 |: S( v- c3 u; F, V2 ?

 3 ?- P, W( X9 n- N
3 ?- P, W( X9 n- N

 4 W/ O/ b0 h7 n) o
4 W/ O/ b0 h7 n) o
